Phonemanalyse
Phoneme sind die kleinsten Anteile unserer gesprochenen Sprache. Jeder Buchstabe der gesprochenen Sprache repräsentiert ein oder mehrere Phoneme. Durch die Kombination von Buchstaben wird mit der Schrift versucht, die verschiedenen Phoneme der gesprochenen Sprache zu symbolisieren (z.b. sch oder kurze Ausprache eines Vokals vor einem Doppelkonsonant, lange Aussprache durch Verdopplung eines Vokals etc.). Im Deutschen gibt es ca. 60 Phoneme. Die Tabelle zeigt vier Phoneme, die in der Schrift mit dem “a” symbolisiert werden. Aber man sieht auch an dem Wort “besser”, dass dieses im normalen Redefluss eher auf einen kurzen A-Laut endet, obwohl es mit “er” geschrieben wird.
|
Bei normalem Sprechtempo mit 2 bis 3 Worten pro Sekunde und einer Frequenz von 100 Phonemanalysen pro Sekunde wird jedes Phonem mehrmals repräsentiert sein, also aus “Magen” wird in dieser Analysestufe: M-M-M-A-A-A-A-A-A-G-G-E-E-N-N-N. Dabei sind gerade die Konsonanten meist nicht eindeutig (Magen/Maden/nagen etc.), da deren Merkmalsvektoren nach der Analyse überlappende Eigenschaften aufweisen können. Ein mögliches ähnliches Ergebnis der Analyse könnte deshalb auch M-N-M-O-A-A-A-G-K-G-E-N-N-N sein. Völlig klar: das erste N ist in Wirklichkeit doch ein M und die Kombination “MOA” gibt es in so häufigen Worten wie Moabit, Samoa und ..., ist also nicht sehr wahrscheinlich. Der Computer analysiert die Übergangswahrscheinlichkeiten der Phonemanteile in ähnlicher Weise mit einem Verfahren, das Hidden-Markov-Modell genannt wird. Bei dieser Analyse werden auch unterschiedliche Sprechtempi normalisiert und Dehnungen oder verschluckte Phoneme kompensiert (“Magn”).
Die Phoneme sind die Buchstaben der Spracherkennung. Alle Wörter, die das Spracherkennungsprogramm erkennen soll, sind phonemisch hinterlegt. Sofern mehrere Aussprachen möglich sind, werden auch verschiedene Ausspracheformen aufgenommen. Das Aussprachelexikon der Spracherkennung ist natürlich auch phonemisch geordnet. Die Organisation erfolgt dabei in Form einer Baumstruktur (statt der Lexeme müssten hier die Phoneme stehen, es geht ja nur um’s Prinzip).
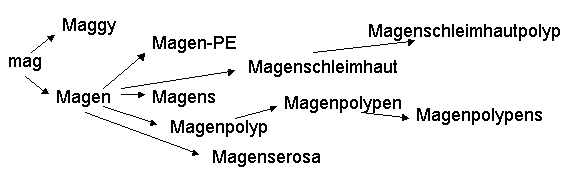 |
Die Baumstruktur verringert den Suchaufwand des Progammes und spart so Rechenzeit.


© 2001-2014
Dr. A. Turzynski
Gemeinschaftspraxis
Pathologie
Lübeck