Im Prozessor
Im Prozessor durchlaufen jetzt die weiteren Schritte. Dabei müssen die sehr umfangreichen Datenmengen zunächst einmal deutlich reduziert werden, indem versucht wird, Muster erkennbar zu machen. Dabei wird analysiert, mit welcher Intensität in bestimmten Frequenzbändern Töne vorkommen. Dieses geschieht durch eine mathematische Analyse, die Fast-Fourier-Transformation genannt wird. Das muss man nicht in Einzelnen verstehen, dafür gibt es ja Mathematiker. Das wichtigste ist aber, dass dieses schnell geschieht, denn während der Computer den Datenstrom analysiert, kommen ja weitere Daten vom Sprecher an und gleichzeitig müssen die vorangegangenen Sprachdaten auf den nachfolgenden Ebenen weiter verarbeitet werden. Eine grafische Falschfarbendarstellung des Ergebnisses einer FFT zweier Wörter ist hier dargestellt. Schon bei der Betrachtung kann man Silben abgrenzen, erkennt ähnliche Laute (z.B. die beiden “o” in Pathologie) und ahnt, dass ich das “i” in Pathologie gedehnt ausgesprochen habe.
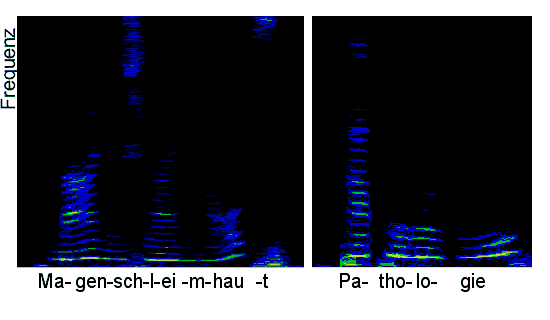 |
Hinter den hier grafisch erkennbaren Lauten verbergen sich die Phoneme, die der Prozessor nun als nächstes zu identifizieren versucht. Dazu werden die noch immer sehr umfangreichen Klanginformationen anhand charakteristischer Merkmale reduziert und mit Hilfe von Merkmalsvektoren beschrieben. In ähnlicher Weise werden übrigens auch beim Hören die Datenmengen der akustischen Information zunächst drastisch reduziert, bevor das Gesagte analysiert wird. Der spracherkennende Computer führt alle 10 msec eine entsprechende Analyse durch. Im Ergebnis erhält er so 100mal pro Sekunde die Information, welches Phonem gerade ausgesprochen wurde.


© 2001-2014
Dr. A. Turzynski
Gemeinschaftspraxis
Pathologie
Lübeck